
The WikiWatershed web application functions by being built from many frameworks and components executed within an Amazon Web Service based cloud infrastructure, most of which is not visible to the user. Its principal design goals are to allow intensive geoprocessing andcspatial modeling for arbitrarily defined geographies and to process variable user loads — all while delivering output at speeds suitable for the web. The entire software stack is open source and available on the WikiWatershed GitHub repository. The following is an explanation of what specific technology is used to achieve that goal.
9.1 Framework Diagram
A simplified architectural diagram showing these high level components.
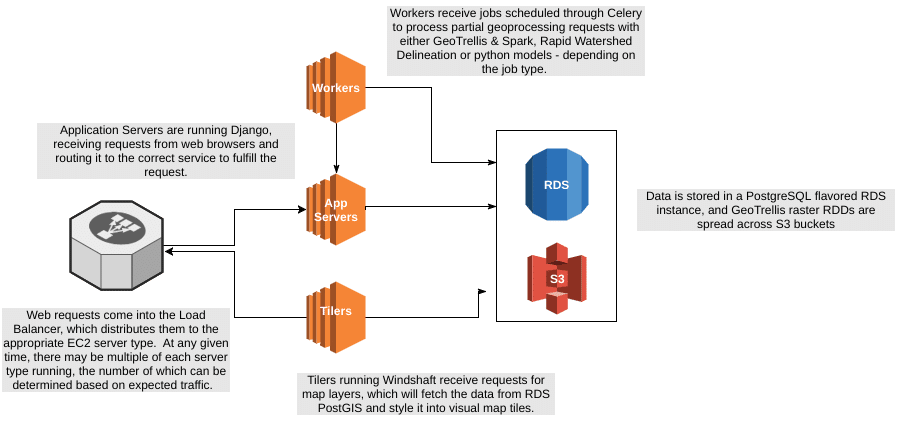
9.2 Computation and Execution
The core functionality of the Model My Watershed web application runs on the following services and frameworks.
Amazon EC2 is the main computation service that provides CPU, memory and I/O (input/output) resources to the application code. The code and its dependencies are compiled into Amazon Machine Images (AMI) which can then be loaded onto EC2 instances and added to a fleet of servers responding to web requests and computing model results. The application decouples various processing roles from each other by isolating logical functionality into their own AMI so that scaling can happen for specific components of the system independently of each other. The main categories of server types are:
- AppServer: handles web requests and initializing modeling jobs
- Worker: handles the asynchronous execution of geoprocessing and modeling tasks
- Tiler: handles requests to generate map tiles from vector based data sources
AWS ElasticLoadBalancer (ELB) and AutoScalingGroups (ASG) are utilized to distribute web traffic to multiple EC2 instances, the number of which can be controlled through an ASG profile, which can increase the capacity of the infrastructure by adding or removing EC2 instances of any particular type.
Celery is an open source distributed task queue. Long-running geoprocessing requests are decomposed into jobs which do partial calculation concurrently across the worker machines, which are then reassembled and returned to the user.
Apache Spark is a fast and general engine for large-scale data processing with tight integration with our main geoprocessing tool, GeoTrellis (see description below).
Spark Job Server is a project providing a standard HTTP based interface into a Spark Context, allowing us to submit Scala based Spark jobs from our Python code.
Django Web Framework is a Python WSGI compatible framework that serves the backend API routes, provides an interface into the backend database, and handles our user authentication workflows.
9.3 Data Storage
Raster analysis and model data are chunked and stored as RDDs, a Spark data format, on Amazon Simple Storage Service, S3. S3 provides low latency, redundantly distributed object storage with an HTTP interface. Our source code can make use of a spatial indexing system allowing us to read subsets of the raster data to do our analyses and modelling routines.
Rapid Watershed Delineation requires disk access to its raster and vector input, which is stored on a snapshot of an Amazon Elastic Block Store (EBS) volume. This data volume can be attached to running instances of the Worker EC2 type as they come online.
Amazon’s Relational Database Service provides us with a general purpose database, with a PostgreSQL compatible protocol. The PostGIS spatial extension is enabled to allow us to store and query geometry data.
9.4 Geoprocessing
GeoTrellis is an open-source raster-focused geoprocessing engine. It is maintained by Element 84 but belongs to LocationTech and Eclipse Foundation open source group.
- Provides raster processing at web speed
- Community support: 6,500 commits, 14 releases; 54 contributors
Windshaft is a web-based map server built on top of Mapnik, a popular vector rendering engine. Windshaft is used to convert our vector data sources into styled map images that can be overlaid or selected in the app.
9.5 Model Execution
Both the Site Storm Model and Watershed Multi-Year Model have been created as open source Python modules, available for installation from the Python Package Index.
The workflow of doing spatial analysis on both vector and raster data sources, aggregating and aligning the intermediate data input and the actual execution of the model is orchestrated through all of the technologies listed above, often in seconds, to produce the results that are provided to the user.
